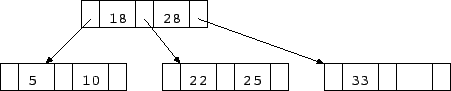
(インデックスのデータ構造: 画像は山口大学の市川教授のWebページから引用)
天体カタログではたいてい「天体ID(objID)」や「天体名」が プライマリキーとなっている. プライマリキーはテーブルの左端のカラムである事が多い.
2011年8月 初版
下記の実習の後,SQLについて「一から」レクシャーしますが, 実は,類推力がある人ならこれだけでも ある程度は使えるようになります.
SQL修得において重要なポイントは,
「GUIによる検索結果ページに表示されるSQL文を使いまわす」
事です.
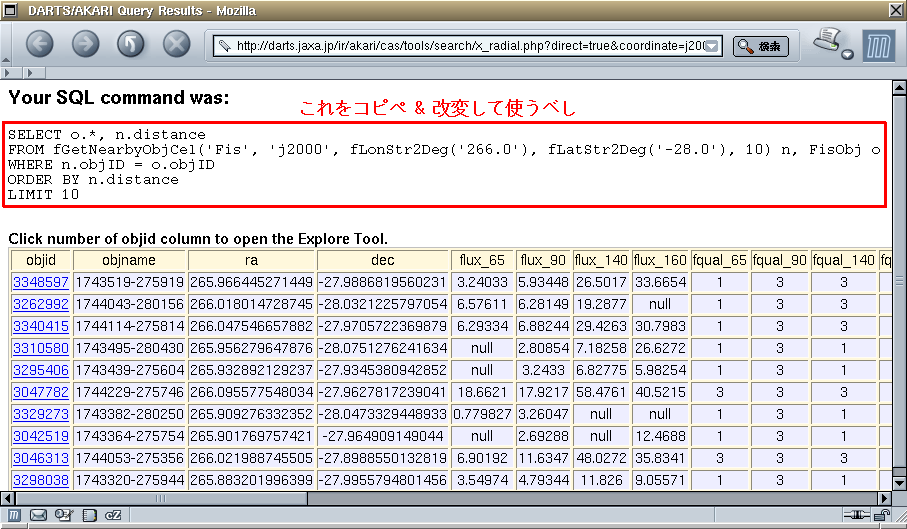
いきなりですが,SQL文で 「あかり」カタログ の Radial Search を試してみましょう. 「そんな無謀な!」と思った貴方,心配ありません. コピペするだけですから.
LIMIT 10」の「10」の部分を変更して,
結果ページに表示される件数が変わるのを確認しましょう.
SQLでの検索・演算は,必ず「SELECT」から始めます.
SQLでは,文字列を除き,大文字小文字は区別されません.
では,最も簡単な
SELECT文
を試してみましょう.
AKARI-CASの SQL Search ページを使います. 本日の実習では,しばらくこのページを使うので, 別ウィンドゥで常に開いておくと便利です.
下記では,SQL文とその結果を示していますので, 手で入力して結果を確認してください.
SELECT 'Hello World'結果↓
| ?column? |
|---|
| Hello World |
SELECT sqrt(1.23^2 + 3.45^2 + 2.34^2)結果↓
| sqrt |
|---|
| 4.3463778022624770 |
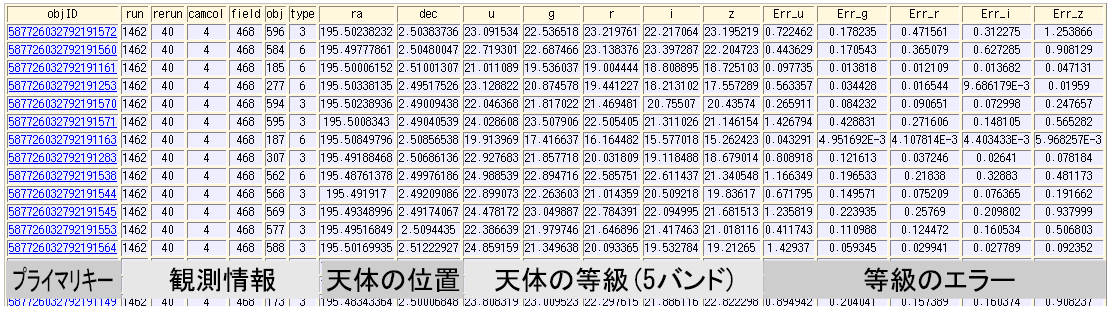
テーブルにアクセスする時のSQL文の基本形は下記のとおりです.
-- この一行はコメント文です SELECT カラム名1,カラム名2,… FROM テーブル名 WHERE 検索条件 LIMIT 表示する件数
「-- 」から始まる部分はコメント文で,
RDBMSはこの部分を解釈しません.
AKARI-CASの
SQL Search
ページで試しながらみていきましょう.
(以下の例文中のテーブルとカラムの説明: IrcObjAll)
SELECT の後に「*」を指定すると,
「すべてのカラム」と解釈されます.
どのようなカラムがあるかを把握する時にも使えます.
SELECT * FROM IrcObjAll LIMIT 10
SELECT の後に「本来のカラム名 AS 別名」と書けば,
表のカラム名を変更できます.
SELECT objid, objname AS tentaimei, ra, dec FROM IrcObjAll LIMIT 10
FROM句の
本来のテーブル名の後に任意の名前を書けば,
表の別名を定義できます.
SELECT o.objid, o.ra, o.dec -- 別名を定義すると,このように使う事が多い FROM IrcObjAll o -- IrcObjAll の別名として「o」を定義 LIMIT 10
SELECTの後では「テーブル名.カラム名」と
書いていますが,これが厳密な書き方です.
SELECT の後に「count(*)」を使うか,
SELECT count(*) FROM IrcObjAll
次のようにプライマリキーで行を数えます.
SELECT count(objid) FROM IrcObjAll
count()の場合も,
インデックスが存在するカラムを指定した方が高速です.
ただし,テーブルが巨大な場合は実行に非常に時間がかかる事があるので, 注意してください.
SELECT の後に「min(column1)」「max(column1)」
を使います.
SELECT min(flux_09), max(flux_09) FROM IrcObjAll
カラムにインデックスが作成されていれば, テーブルが巨大な場合でも瞬時に求まります.
データベース製品によって異なります.
LIMIT 行数」と書きます.
SELECT * FROM IrcObjAll LIMIT 10
SELECT」の直後に「TOP 行数」と書きます.
SELECT TOP 10 * FROM PhotoObjAll
続いて,AKARI-CASの SQL Search ページを使います.
IrcObjAll」のカラム
「objID」,
「objName」,
「ra」,
「dec」,
「flux_09」,
「flux_18」
について,最初の20件について表示してください.
ra」「dec」
のカラム名を
「lon」「lat」に変更したテーブルを
表示してください.
検索を実行する時は,
SELECT … FROM …
WHEREの後に条件
を書きます.
SELECT カラム名1,カラム名2,… FROM テーブル名 WHERE 検索条件
検索条件を書く時は,次のような演算子・関数を使う事ができます.
(以下の例文中のテーブルとカラムの説明: IrcObjAll)
AND」,「OR」,「NOT」=」(「==」ではありません!),
「>」,「<」,
「>=」,「<=」,「!=」
SELECT *
FROM IrcObjAll
WHERE
( 19.5 < flux_09 AND flux_09 <= 20.0 ) AND
( fQual_09 = 3 OR fQual_18 = 3 )
個人的には,値の区間を表現したい場合での
「>」「>=」
の使用は勧めません.不等号の使用を
「<」「<=」
に限定し,「左側を小」「右側を大」と決めておけば,
値の区間を視覚的に理解しやすく,間違いにくくなります.flux_09が区間内にある条件でしたが,
区間外の場合は次のように記述する事をお勧めします.
( flux_09 <= 19.5 OR 20.0 < flux_09 ) AND
column1 BETWEEN 10 AND 20」SELECT * FROM IrcObjAll WHERE flux_09 BETWEEN 19.5 AND 20.0
WHERE flux_18 IS NULL
WHERE flux_18 IS NOT NULLNULL とは「入れるべき値が無い」状態の事です. NULL なセルが存在するかどうかは,カラムによって異なります.
null」で表現される.0」,「0.0」
などが使われ,わかりにくい.
WHERE column1 LIKE 'NGC %'
%」,累乗「^」,
絶対値「@」などなど.
abs(),exp(),
round(),sqrt(),power(),
sin(),atan2()
などなど.
続いて,AKARI-CASの SQL Search ページを使います.
IrcObjAll」について,
カラム「flux_09」の値が17.5から18.0であり,
かつ
カラム「fQual_09」,
「fQual_18」の値が
3 のものが何件あるかを調べてください.
RDBMSというものは,
1つのSQL文について「ただちに結果が返ってくる」
ように利用するものです.
もし,検索に時間がかかりすぎる場合は,
質の悪いWHERE句を書いている可能性が高いのです.
検索に時間がかかりすぎると,利用者本人がイライラするだけではなく,
不必要にサーバに負担をかける事にもなります.
注意しなければならないのは, 「WHERE」句の式は,一般的なプログラミング言語と同じ感覚で 書いてはいけない 事です. ここでは,検索で遅くならないための「基本」を身につけましょう.
続いて,AKARI-CASの SQL Search ページを使います.
fJy2ABmag(),
fABmag2Jy() という関数で,AB等級⇔Jy 相互の変換が可能です.
次のSQL文を実行して,Jy と等級との両方が表示される事を確認してください.
SELECT objid,
flux_09, fjy2abmag(flux_09) AS mag_09,
flux_18, fjy2abmag(flux_18) AS mag_18
FROM ircobjall
WHERE fQual_09 = 3 AND fQual_18 = 3
LIMIT 10
SELECT objid,
flux_09, fjy2abmag(flux_09) AS mag_09
FROM ircobjall
WHERE 13.0 < fjy2abmag(flux_09)
SELECT objid,
flux_09, fjy2abmag(flux_09) AS mag_09
FROM ircobjall
WHERE flux_09 < fabmag2jy(13.0)
なぜ最初のWHERE句の書き方がマズいのでしょう? 「ピン」ときましたか?
最初のものがマズい理由を考えるにあたって, 天体カタログDBを使う上で最低限の知識 で述べたインデックスの仕組み,すなわち 「RDBMSでの高速検索のためには, 表のカラム・データに対してインデックスが使われる必要がある」 という事を思い出してください.
最初の「WHERE 13.0 < fjy2abmag(flux_09)」
では,RDBMSは「fjy2abmag(flux_09)に対して検索」と
解釈します.
しかし,インデックスが作成されているのは,
あくまでflux_09の値そのものですから,
fjy2abmag(flux_09)のように演算をかまされると,
インデックスは使えないのです.インデックスが使用不可となれば,
RDBMSは結局,カラムflux_09の全部の行に対して
fjy2abmag()関数の計算を行なって,
順に条件を評価するハメになり,遅くなるわけです.
したがって,遅くならない「WHERE」句の書き方の掟は, 「WHERE句でカラム・データに対して演算をしない事」 だと言えます. この掟は,今日の講習では最重要な知識ですから, 絶対に忘れないようにしたいものです.
ここで述べた基本を守りつつ, 難しい条件での検索をいかにパフォーマンスを落とさずに行えるかが, SQLというパズルにおいて最も重要な局面なのです.
この講習会ではとりあげませんが,
カラム・データに対して演算をしている場合でも
インデックスを使う技があります(式に対するインデックス(式インデックス)).
fjy2abmag(flux_09)のような場合は式インデックスを作る事ができますが,
関数の引数に検索条件が入ってくる場合はインデックスは作れません.
WHERE句の後に「ORDER BY xxx」
を指定すると,昇順,降順またはランダムに並び換えができます.
SELECT カラム名1,カラム名2,… FROM テーブル名 WHERE 検索条件 ORDER BY xxx
ORDER BY カラム名」
ORDER BY カラム名 DESC」
ランダムに並び換える場合は,RDBMS製品によって異なります.
ORDER BY random()」
ORDER BY rand()」
上記は,すべての行に対して浮動小数点型の乱数を発生させ, その値によって並び換えを行う事を意味します. したがって, 巨大なテーブルに対してはこの方法はあまりに時間がかかりすぎるため, 不適切と言えます.
参考: 巨大なテーブルからのランダム抽出については, 巨大テーブルとの付き合い方 --- 4.7億天体の2MASS PSCで実習 をご覧ください.続いて,AKARI-CASの SQL Search ページを使います.
IrcObjAll」について,
カラム「flux_09」の値がAB等級で12.2等より暗い天体を検索し,
フラックスの昇順で並べ変えてください.
取得するカラムは,objidとフラックス(Jy と AB等級)
とします.
もっと学びたい人は 「行の並び替え」をどうぞ.
次のような構文を使うと,検索した結果テーブルに対して, さらに条件を絞り込んで検索する事ができます.
SELECT o.*
FROM -- 次の()の中は表を返すものならどんな SELECT 文でも良い
(
SELECT column1, column2, … -- ここは単に「SELECT *」でも良い
FROM table_name
WHERE column1 < 123
) o -- () を実行後の結果テーブルを「o」と名づける
WHERE o.column2 < 345
()の中に書いたものをサブクエリといい,
検索は,まずサブクエリのSELECT文が実行され,
その後に外側のSELECT文が実行されます.
ただし,インデックスが使われるのは内側のSELECT文だけである
という点に注意してください.
()の中のSELECT文の
結果テーブルに対して
任意の名前をつけ(上記の例では「o」),
それを外側のSELECT文からは
名前つきで使う事がポイントです.
わざわざこんな事をしなくても,1つのSELECT文で
WHERE以下でANDを使って
ズラズラと条件をつなげれば良い気がしますが,その場合は
検索のアルゴリズムはRDBMSが勝手に決めるので,
どのようにインデックスが使われるかは明らかではありません.
FROM句でのサブクエリを使う事により,
確実に意図したカラムのインデックスを使って検索をさせる事ができます.
また,きちんと整形されたサブクエリのSQL文により,
検索ロジックを明確にする事ができます.
もう1つサブクエリが有効なのは,表の結合 の時です. 表の結合についてはこの後で実習しますが, サブクエリにより,結果テーブルを既存のテーブルに結合できます.
続いて,AKARI-CASの SQL Search ページを使います.
IrcObjAll」について,
カラム「flux_09」の値がAB等級で12.2等より暗いものを
検索して結果を確認し,さらに
FROM句でのサブクエリを使って,結果テーブルの
nScanC_09(サーベイにおいて天体が検出された回数)
の値が 6 以上のもののみ選んでください.objid,フラックス(Jy と AB等級),
nScanC_09
とします.
サブクエリとして重要で奥が深いものに,
WHERE句でのサブクエリがあります.
EXISTS,ALL
等をWHERE句のサブクエリで使うと,
かなり高度な検索ができます.
ここでは比較的良く利用する EXISTS を使った
サブクエリを取り上げます.
AKARI-CASには,「あかり」カタログの天体1つ1つについてを,
SIMBADとNEDに座標で問い合わせた結果がテーブルに保存されています.
そのテーブルの1つが「SimbadIrc」です.
ここでは,「あかり」IRCカタログの中にSIMBADのデータが存在するものが
何件あるかを調べてみます.
その前に,テーブル「SimbadIrc」の内容を
ちょっと確認しておきましょう.
次のSELECT文を,AKARI-CASの
SQL Search
ページから実行してみましょう.
SELECT * FROM SimbadIrc LIMIT 10
テーブル「SimbadIrc」のカラムには,
「oid」「objid」
が含まれていますね.
このうち前者はSIMBADデータベースの天体IDで,
後者は「あかり」カタログの天体IDです.
objidは重複する場合があり,
単純にSimbadIrc上のobjidを数えても
件数を取得できません.
このような場合には,
WHERE EXISTS (...)
の構文を使います.
SELECT count(o.objid) FROM IrcObjAll o WHERE EXISTS ( SELECT * FROM SimbadIrc s WHERE o.objid = s.objid )
WHERE EXISTS (...)は「(...)で見つかったものすべてを取り出す」
という事を意味しています.
このSQL文では,サブクエリ内の条件「WHERE o.objid = s.objid」が
(...)の外側のテーブル「IrcObjAll」を参照していますが,
このような形を「相関サブクエリ」と呼んでいます。
参考1: TECHSCORE サブクエリ
参考2: 副問い合わせ式
┌──────────┐ ┌────────┐ ┌──────────────┐│ │ │ │ │ │├──────────┤ ├────────┤ ├──────────────┤│ │ │ │ │ ││ │ │ │ │ ││ 表A │+│ 表B │=│ 表C ││ │ │ │ │ ││ │ │ │ │ ││ │ │ │ │ │└──────────┘ └────────┘ └──────────────┘のように,複数の表を横方向に結合する事を「ジョイン」といい, RDBMSでは複雑な条件による結合でも簡単にできてしまいます.
この「ジョイン」のうち, 表の結合のための条件を完全に満たす行のみ取り出して, 2つのテーブルを結合する事を, 「ナチュラルジョイン」といいます. 別の言い方をすれば, 2つの表で互いに結びつく行のみを取り出して結合する という事になります.
さきほど,「あかり」カタログの天体についての
SIMBADのテーブル
SimbadIrc
を使いました.
これに,物理量のカラムを追加したものが
「SimbadIrcAll」であり,
今度はこれと「あかり」IRCカタログとをナチュラルジョインしてみます.
その前に,テーブル「SimbadIrcAll」の内容を
ちょっと確認しておきましょう.
次のSELECT文を,AKARI-CASの
SQL Search
ページから実行してみましょう.
SELECT * FROM SimbadIrcAll LIMIT 10
SimbadIrc
と同様,
「oid」「objid」
が含まれていますね.
つまり,両者に
「あかり」カタログの天体ID(objid)が存在するわけですから,
「両者のobjidが等しい」を条件に
2つのテーブルを
結合できるわけです.
ナチュラルジョインには,二通りの書き方があります.
AKARI-CASの
SQL Search
ページから実行し,同じ結果が得られる事を確認してください.
SELECT o.objid, o.objname, o.ra, o.dec, -- AKARI IRCカタログのカラム
o.flux_09, o.flux_18,
s.* -- SIMBADデータのカラム
FROM IrcObjAll o, SimbadIrcAll s
WHERE o.objid = s.objid -- 結合条件
LIMIT 10
JOIN 結合するテーブル ON 結合条件」を使う方法:
SELECT o.objid, o.objname, o.ra, o.dec,
o.flux_09, o.flux_18,
s.*
FROM IrcObjAll o
JOIN SimbadIrcAll s
ON o.objid = s.objid
LIMIT 10
| objid | objname | ra | dec | flux_09 | flux_18 | oid | primident | ra | dec | type | spectype | morphtype | u | b | v | r | i | j | h | k | objid | orderdistance | distance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 200810849 | 2100534+373911 | 315.222574200031 | 37.6531066001437 | 0.272824 | null | 3 | HD 200207 | 315.222412 | 37.653106 | * | G5 | null | null | 9.1 | 8.12 | null | null | 6.335 | 5.877 | 5.769 | 200810849 | 1 | 0.0077051073103068 |
| 200806802 | 2053597+365346 | 313.499159600094 | 36.8962510000732 | 0.15966 | null | 7 | BD+36 4307 | 313.49912 | 36.896514 | * | K0 | null | null | 10.32 | 9.08 | null | null | 7.148 | 6.564 | 6.424 | 200806802 | 1 | 0.015893981914779 |
| 200807004 | 2054183+365743 | 313.576366999449 | 36.9621255002141 | 0.0805052 | null | 9 | BD+36 4310 | 313.575976 | 36.961907 | * | K0 | null | null | 9.7 | 9.01 | null | null | 7.753 | 7.443 | 7.38 | 200807004 | 1 | 0.022874876104798 |
| 200807244 | 2054419+370425 | 313.674936600034 | 37.0738798001524 | 0.094013 | null | 10 | CCDM J20547+3704AB | 313.674985 | 37.073708 | ** | A0 | null | null | 7.17 | 7.15 | null | null | null | null | null | 200807244 | 1 | 0.010565192737169 |
| 200807253 | 2054424+371352 | 313.676908499895 | 37.2311945000047 | 0.136734 | null | 11 | BD+36 4315 | 313.676905 | 37.231448 | * | K | null | null | 11.7 | 10.38 | null | null | 7.942 | 7.29 | 7.133 | 200807253 | 1 | 0.015210882653645 |
| 200807910 | 2055476+363739 | 313.94840299974 | 36.6277370001017 | 0.109572 | null | 13 | BD+36 4324 | 313.948448 | 36.627702 | * | K0 | null | null | 10.54 | 9.36 | null | null | 7.428 | 6.914 | 6.792 | 200807910 | 1 | 0.0030175795850996 |
| 200808257 | 2056218+364547 | 314.091089666719 | 36.7631393335245 | 0.396598 | null | 14 | BD+36 4326 | 314.091202 | 36.76316 | * | K5 | null | null | 10.91 | 9.37 | null | null | 6.471 | 5.752 | 5.515 | 200808257 | 1 | 0.0055400371287732 |
| 200808873 | 2057259+370936 | 314.358238833335 | 37.1600511668025 | 0.0994696 | null | 18 | BD+36 4335 | 314.358113 | 37.160073 | * | G0 | null | null | 10.01 | 9.16 | null | null | 7.461 | 7.031 | 6.914 | 200808873 | 1 | 0.0061578331756021 |
| 200809309 | 2058105+365833 | 314.544007333553 | 36.9760965000689 | 0.370555 | null | 21 | BD+36 4342 | 314.544128 | 36.976146 | * | K5 | null | null | 10.53 | 9.11 | null | null | 6.404 | 5.715 | 5.524 | 200809309 | 1 | 0.0065019221578094 |
| 200809607 | 2058389+370240 | 314.662135400712 | 37.0446446005659 | 0.1029 | null | 22 | BD+36 4345 | 314.662213 | 37.044765 | * | K0 | null | null | 10.27 | 9.31 | null | null | 7.502 | 7.082 | 6.966 | 200809607 | 1 | 0.0081238704698035 |
ナチュラルジョインでは,表の結合のための条件を完全に満たす行のみを 選んでいましたが, 「レフトジョイン」の場合は,条件を完全に満たさない場合も, 左側のテーブルについてはすべてを出力します.
結合条件に合わず,結びつけるべき行が右側のテーブルに存在しない場合,
セルはすべて「null」で埋められます.
構文はナチュラルジョインの2つめの書き方と同じで,
「LEFT JOIN 結合するテーブル ON 条件」とします.
| objid | skyversion | run | rerun | fieldid | ||
|---|---|---|---|---|---|---|
| 587722951693303809 | 1 | 745 | 40 | ... | 587722951693303808 | ... |
| fieldid | psfwidth_u | psfwidth_g | psfwidth_r | ||
|---|---|---|---|---|---|
| 587722951693303808 | ... | 1.53136 | 1.4194 | 1.362953 | ... |
| objid | skyversion | run | rerun | fieldid | psfwidth_u | psfwidth_g | psfwidth_r | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 587722951693303809 | 1 | 745 | 40 | ... | 587722951693303808 | ... | 1.53136 | 1.4194 | 1.362953 | ... |
AKARI-CASの
Match-up AKARI catalogues with Cached SIMBAD/NED catalogs
を使えば,
「M %」(メシエ天体の場合),
「NGC %」(NGC天体の場合)
と入力するだけで,SIMBADあるいはNEDのデータと「あかり」カタログとを
瞬時に結合する事が可能です.
みなさんが知っているカタログに「あかり」天体が存在するか, 確認してください.
AKARI-CASのSIMBADのデータを保存したテーブル
「SimbadCache」
「SimbadIdent」
「SimbadFis」
「SimbadIrc」
が,どのような関係を持っているかを調べてください.
SQL Schema: Tables
にテーブルの解説があります.
天体カタログには, 天体種別・スペクトル型のような「天体の分類情報」が含まれている事が あります. このような時,どの種別あるいはどの型の天体がいくつあるかを 調べたくなるものです.
このような場合もSQLなら「GROUP BY」と「count()」
を使えば簡単に結果を得られます.
さきほどのSIMBADのテーブル「SimbadIrcAll」には,
type,
specType,
morphType
というカラムがありました(データは文字列).
このうち,typeはSIMBADデータベースにおける
天体種別,
specTypeはスペクトル型,
morphTypeは形態型を示しています.
それでは,「あかり」IRCカタログには
どんなSIMBAD登録天体がどれくらいいるのかを,
GROUP BYを使って簡単に調べてみましょう.
SELECT type, count(type) FROM SimbadIrcAll WHERE orderDistance = 1 GROUP BY type ORDER BY count
orderDistanceは,
1つのSIMBAD天体に対し,複数の「あかり」天体がヒットしている場合,
距離の近い順に,1,2,3,.. の順にセットされているものです.
従って,SIMBAD天体と「あかり」天体とを"一対一"の関係にするには,
orderDistanceが 1 のものに
限る必要があるわけです.
ではさらに,specType,
orderDistance,
についても集計してみましょう.
SELECT type, count(type) as cnt_t,
specType, count(specType) as cnt_s,
orderDistance, count(orderDistance) as cnt_o
FROM SimbadIrcAll
GROUP BY type, specType, orderDistance
ORDER By type
LIMIT 100
type→specType→orderDistance
のように複数のカラムを階層的に集計する事もできます.
2つ前の例文では,orderDistanceが1だけのものを集計するのに,
WHERE句を使いましたが,
実はこのような場合は,次のようにHAVING句を使うのが正解です.
SELECT type, count(type) as cnt_t,
specType, count(specType) as cnt_s,
orderDistance
FROM SimbadIrcAll
GROUP BY type, specType, orderDistance
HAVING orderDistance = 1
ORDER By type
LIMIT 100
HAVING句は,GROUP BYの後に書き,
グループ化した後からある条件に合うグループだけを選択(不要なグループを除去)
するために使います.
これにより,SQLでは非常に柔軟な集計が可能になっているわけです.
参考: テーブル式
specType が NULL のものを
集計結果から除去してください.
IrcObjAll」の
カラム「nScanP_09」
を使って,空のスキャン回数の分布を
「GROUP BY」と「count()」とを使って
簡単に調べてください.
nScanP_09で並び換えるとその分布が直感的に把握できます.
posErrMj」)について,
サンプリング間隔が 0.1 のヒストグラムのためのデータを作成してください.
floor()関数を使うと良いでしょう.
次のようにすると,最も多い天体種別は何かを調べる事ができます.
SELECT type, count(*)
FROM SimbadIrcAll
GROUP BY type, orderDistance
HAVING orderDistance = 1 AND
count(*) >= ALL (SELECT count(type)
FROM SimbadIrcAll
GROUP BY type, orderDistance
HAVING orderDistance = 1)
「左辺 >= ALL (…)」は,
「(…)の結果すべてに対して,左辺が等しいか大きい場合に真」
を意味します.
参考1: CodeZine HAVING句の力
参考2: 副問い合わせ式
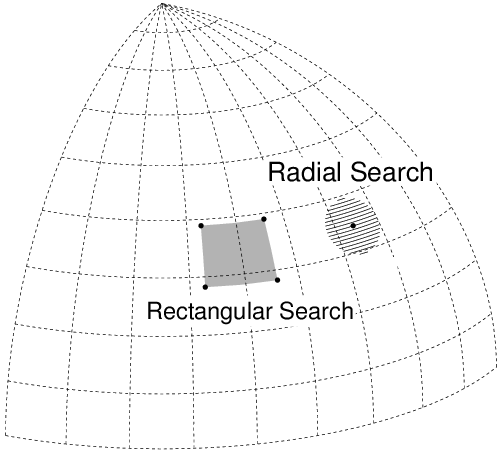
天球上のあるポジションからある角度半径内の天体を検索する Radial Search (コーンサーチとも呼ばれる) は,天文屋にとっては最も良く使う検索である. ここでは,RDBMSでどのようにして高速な Radial Search を実現しているかを解説する.
試しに,「あかり」IRCカタログについて,この検索を素直にSQL文に書き下してみる. テーブル中のxyz座標(単位ベクトル; 値の範囲は0.0から1.0)を使うと余弦定理で2点間の角度が簡単に求まり, 次のように書ける(テーブル中の天体座標はcx,cy,czである).
SELECT * FROM IrcObjAll WHERE acos( (2.0 - ((cx-位置x)^2 + (cy-位置y)^2 + (cz-位置z)^2) ) / 2.0 ) <= 角度半径
しかし,このSQL文では検索に非常に時間がかかるのは明白である. 「遅くならない『WHERE句』の書き方の掟」 で示したとおり, カラム・データに対して演算をしてしまっているので, インデックスは使われないからである.
このような場合,RDBMS上での実装の定石は,
のように,検索を2段階に分ける事である.
当然,天文業界ではすでにいくつかの手法が確立しており, 本講義ではそのうちの2つを紹介する.





天球分割の方法に比べ,実装が単純で小さめの検索半径の時に 非常に高速に検索が可能である.
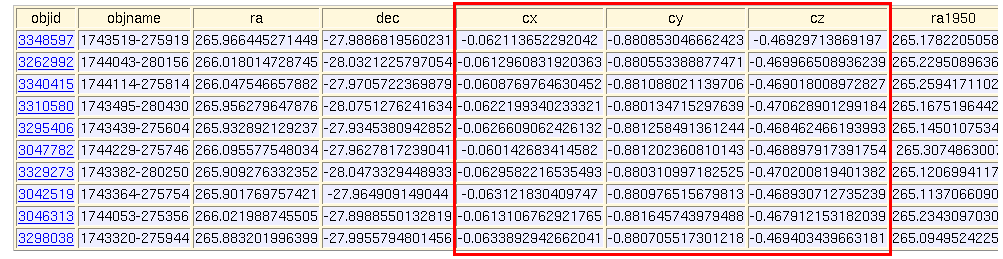
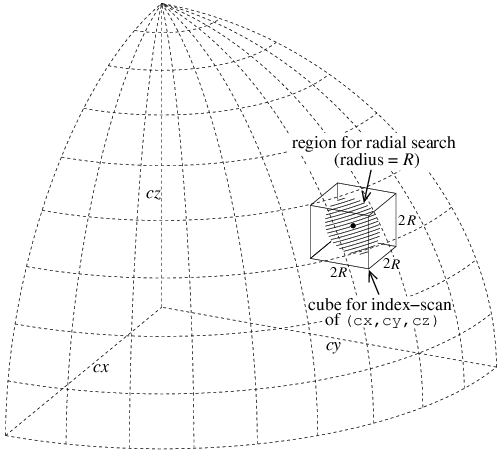
次の手順に従って, 「あかり」IRCカタログについて, 検索座標(ra=188.580537[deg],dec=6.467703[deg]),直交座標では(cx=-0.982513866380272,cy=-0.148249882182357,cz=0.112643130298329) から半径 R= 0.02 ラジアン内の天体を検索してください.
WHERE (cx BETWEEN xmin AND xmax) AND (cy BETWEEN ...」
の形を使って,
検索座標を中心とする一辺 2R の立方体内にある天体を
IrcObjAllテーブルから検索し,
カラム
objid, objname, ra, dec, cx, cy, cz
のデータを取得してください.
SQL文で使える関数は「ストアド関数」と呼ばれ, 関数の返り値は 3 通りあります.
PostgreSQLでは,
generate_series()
というテーブルを返すビルトイン関数があります.
返り値がどのようになるかを確認してください.
SELECT * FROM generate_series(1, 32)
SQLの修得のコツ で動かしてもらったRadial Searchは, 実はストアド関数を使ったものでした.
Radial Search や Rectangular Search のように,天文屋が頻繁に使う位置検索については, 検索システムの構築者が高性能なストアド関数を仕込んでくれている事があります. その場合は,必ずそれらを利用します.
ここでは,SDSSの場合と,AKARI-CASの場合とを紹介します.
fGetNearbyObjCel()」を使います.
SELECT *
FROM fGetNearbyObjCel('irc', 'j2000', 182.0471, 2.8788, 40.0)
↓結果| objid | cx | cy | cz | distance |
|---|---|---|---|---|
| 200230592 | -0.998249186837412 | -0.0410901901010314 | 0.0425459428842157 | 32.3001928457318 |
| 200230103 | -0.998101134950297 | -0.0356702054782602 | 0.0502171370357559 | 0.0292825193690772 |
| 200229557 | -0.997853118240395 | -0.0292182330415348 | 0.0586127057543908 | 36.4052202742836 |
| 200230299 | -0.997809530749764 | -0.0378784399719648 | 0.0542343445634383 | 15.7625018161117 |
| 200230559 | -0.997697265716318 | -0.0407807117445279 | 0.0541950139015745 | 22.2778445153093 |
SELECT o.objid, o.objname, o.ra, o.dec,
o.flux_09, o.flux_18,
f.distance
FROM ircobj o,
fGetNearbyObjCel('irc', 'j2000', 182.0471, 2.8788, 40.0) f
WHERE o.objid = f.objid
↓結果| objid | objname | ra | dec | flux_09 | flux_18 | distance |
|---|---|---|---|---|---|---|
| 200230592 | 1209257+022618 | 182.357093 | 2.43843900000008 | 0.212633 | null | 32.3001928457318 |
| 200230103 | 1208112+025242 | 182.046769333306 | 2.87844066672603 | 0.075916 | 0.529177 | 0.0292825193690772 |
| 200229557 | 1206425+032136 | 181.677204 | 3.3601865 | 0.178772 | null | 36.4052202742836 |
| 200230299 | 1208417+030632 | 182.173995199999 | 3.10892440000033 | 0.406523 | null | 15.7625018161117 |
| 200230559 | 1209217+030624 | 182.3406526 | 3.1066676000005 | 0.243577 | null | 22.2778445153093 |
fGetNearbyObjEq()」を使います.SELECT * FROM fGetNearbyObjEq(182.0471, 2.8788, 0.5)↓結果
| objID | run | camcol | field | rerun | type | cx | cy | cz | htmID | distance |
|---|---|---|---|---|---|---|---|---|---|---|
| 587726015606685723 | 1458 | 4 | 382 | 40 | 3 | -0.99810157 | -0.03566194 | 0.05021442 | 14846242813230 | 0.05731578 |
| 587726015606685730 | 1458 | 4 | 382 | 40 | 3 | -0.99810009 | -0.03570173 | 0.05021554 | 14846242735641 | 0.09265617 |
| 587726015606685736 | 1458 | 4 | 382 | 40 | 3 | -0.99809836 | -0.03579129 | 0.05018606 | 14846310057009 | 0.41682857 |
| 587726015606685734 | 1458 | 4 | 382 | 40 | 3 | -0.99809764 | -0.03580067 | 0.05019376 | 14846310070453 | 0.44080137 |
PhotoObjAllと
関数による結果テーブルとを objID を使ってジョインします.SELECT p.objid, p.ra, p.dec, p.u, p.g, p.r, p.i, p.z, f.distance FROM photoobj p, fGetNearbyObjEq(182.0471, 2.8788, 0.5) f WHERE p.objid = f.objid↓結果
| objid | ra | dec | u | g | r | i | z | distance |
|---|---|---|---|---|---|---|---|---|
| 587726015606685723 | 182.04629444 | 2.87828477 | 15.363654 | 13.597462 | 12.750392 | 12.363647 | 12.105381 | 0.05731578 |
| 587726015606685730 | 182.04857861 | 2.87834891 | 18.717392 | 22.014599 | 24.43655 | 23.825893 | 18.96513 | 0.09265617 |
| 587726015606685734 | 182.05425605 | 2.87709976 | 21.464825 | 20.805237 | 20.493608 | 20.357042 | 21.63262 | 0.44080137 |
| 587726015606685736 | 182.05371694 | 2.8766576 | 21.552475 | 20.821678 | 20.937908 | 21.535532 | 22.231407 | 0.41682857 |
位置,半径を変えて, AKARI-CASの SQL Search でいろんなRadial Searchをしてみましょう.
データベースに複数の天体カタログが存在する場合, それらは簡単に座標マッチアップが行える可能性があります.
fGetNearestObjIDEq() を使えば簡単にマッチアップが
可能です.
AKARI-CAS上で,「あかり」衛星によるFISカタログとIRCカタログとを 座標によりマッチアップする問題です.
fGetNearestObjIDEq()の引数は,順に,
'fis'または'irc')
objidです.FisObjAllテーブル)の右端に,
IRC天体のobjidを追加したテーブルを最初の100件を
表示させてください.サーチ半径は 1.0 [arcmin] としてください.SELECT objid,ra,dec, fGetNearestObjIDEq(_____, ____, ____, 1.0) as objid_irc FROM FisObjAll LIMIT 100
fGetNearestObjIDEq()による
マッチアップ結果として,IRCカタログを
ナチュラルジョインしてください.
サーチ半径は 1.0 [arcmin] としてください.
結果テーブルとして,それぞれの
objid,J2000座標,
FIS天体からの角度(fDistanceArcMinEq()を使う)
を取得してください.
SELECT p.objid, p.ra, p.dec,
q1.objid, q1.ra, q1.dec,
fDistanceArcminEq(p.ra,p.dec,q1.ra,q1.dec) as distance
FROM FisObjAll p
JOIN IrcObjAll q1
ON fGetNearestObjIDEq(_____, ____, ____, 1.0) = q1.objID
LIMIT 100
SELECT p.objid, p.ra, p.dec,
q1.objid, q1.ra, q1.dec,
fDistanceArcminEq(p.ra,p.dec,q1.ra,q1.dec) as distance1,
q2.objid, q2.ra, q2.dec,
fDistanceArcminEq(p.ra,p.dec,q2.ra,q2.dec) as distance2
FROM ...
AKARI-CAS では,日常的によく使いそうな関数をいくつか用意しています. 下記に例を示しましたので,動かしてみてください.
SELECT objid, ra, dec,
fDeg2LonStr(ra) as ra_hms, fDeg2LatStr(dec) as dec_dms
FROM ircobjall
LIMIT 5
xx:xx:xx.x → deg の変換
SELECT flonstr2deg('12:08:11.30'), flatstr2deg('+02:52:43.7')
SELECT objid, ra, dec,
fJ2l(ra,dec) as l, fJ2b(ra,dec) as b,
fJ2lambda(ra,dec) as lambda, fJ2beta(ra,dec) as beta
FROM twomass
LIMIT 5
SELECT objid, ra, dec,
(fGetNearestObjEq('irc',ra,dec,20)).objCount
FROM ircobjall
LIMIT 5
1行の複数のカラムを返す関数の結果から,1つのカラムデータを取り出す時は,
(function(…)).element のようにします.
参考1: AKARI-CASのSQL関数のリファレンス
参考2: SDSS DR8 SkyServerのSQL関数のリファレンス
テーブルの行数が1千万行くらいになると, 全ての行についての検索はインデックスを使わないと かなり厳しくなってきます. また,構築者側の事情として, インデックスの作成に時間がかかり, インデックスのためのデータがディスクを消費するという問題があります. したがって,特に一億を越えるような大規模カタログの場合には, データベース上でインデックスが作成されているカラムは, 「プライマリキー」「座標」「フラックス」程度に限定されていると考えた方が良いでしょう.
小規模カタログではかなり自由にテーブル全体に対して検索・集計が可能でしたが, 大規模カタログを複雑な条件で検索する場合は, 次のような使い方が前提になってきます.
もし,どうしても インデックスが作成されていないカラムを 一番最初の検索条件に含まなければならない場合は, データセンターの人に助けを求めると良いでしょう.
巨大テーブルから直接ランダムに抽出したい場合,
PostgreSQLの場合は次のようにobjidをランダムに
発生させ,カタログのテーブルとジョインする方法があります.
次の例では,AKARI-CASにて,約4.7億行の2MASSカタログ
(テーブル「twomass」)から,
約100件(乱数が重複した場合は100件未満)をランダムに取り出します.
random()関数が
0.0〜1.0
の範囲の値を返す事と,
objidが500000001から連続した数字である事を
利用しています.
SQL Search
で試してみましょう.
SELECT o.* FROM twomass o WHERE EXISTS ( SELECT * FROM ( SELECT 500000001 + CAST(floor(470992970*random()) AS INTEGER) AS rid FROM generate_series(1, 100) ) f WHERE o.objid = f.rid )
generate_series()は,
「ひとやすみ: SQLで使える関数の種類」
で実習しました.
CAST(value AS type)は型を変換するために使う構文です.
上の例では,浮動小数点数を整数(4バイト)に変換しています.
なお,CAST()で浮動小数点数を整数に変換する場合,
RDBMS製品によって四捨五入か切り捨てかが異なりますので,
上記のように必ずfloor()を使ってから型変換します.
次の例は,上記と同じ事をナチュラルジョインを使って書いたものです.
SELECT o.*
FROM (
SELECT 500000001 + CAST(floor(470992970*random()) AS INTEGER) AS rid
FROM generate_series(1, 100)
GROUP BY rid -- 重複を避けるために使用
) s
JOIN twomass o
ON o.objid = s.rid
JOINを使った場合よりも WHERE EXISTSの方が
やりたい事を素直にSQL文に表現できており,
こういう場面では前者の書き方をお勧めします.
MS SQL Serverを採用している
SDSS SkyServerではgenerate_series()が使えません.
そのかわり,htmIDと呼ばれる天域IDを使ってランダム抽出する方法が
Webページ
に紹介されています.
AKARI-CASでは,2MASS PSCについても ストアド関数を使ってらくらく位置検索 で示したようにストアド関数で位置検索が可能です.
twomass」について,
ra=162.991850[deg],dec=+03.792003[deg],半径5.0[arcmin] のRadial Searchを
fGetNearbyObjCel()を使って行なってください.
結果は,検索位置からの角度が小さいものが先頭になるように並び換え,
テーブル「twomass」のカラムはすべて取得してください.
なお,fGetNearbyObjCel()の第一引数は,
'twomass'とします.
twomassテーブルの
カラム dist_opt が null
ではないものだけを取り出してください.
確実に座標検索を先に行わせるため,
FROM句でのサブクエリを使ってください.今度は,位置検索により2MASS PSCの天体をランダムに抽出してみましょう.
generate_series(),
random(),
fGetNearestObjIDEq()
を使って,サーチ半径 3 [arcmin] のランダムな座標検索により,
約100天体のobjidを求めてください.degrees()関数を使います.
twomassテーブルの全カラムを取得してください.
SDSS DR8で分光観測された天域に存在するすべての「あかり」IRC天体を, 次の手順で検索してみましょう.
SDSSの分光観測では,視野半径1.49[deg]の円形アルミ板プレートのターゲット位置に
ファイバーを手で差し込み,これを
望遠鏡に取り付けて天体に向けます.
このプレートでどの天域が観測されたかは,
SkyServerの「sdssTileAll」というテーブルに格納されています.
このテーブルの tile がプライマリキー,
raCen,decCenがJ2000でのプレートの中心座標です.
sdssTileAll」のプライマリキーと中心座標のみを,
csv形式で取得してください.
$ wget http://www.ir.isas.jaxa.jp/~cyamauch/adc2011sql/getakaribylist.php.gzこのPHPスクリプトは,引数で指定された csv ファイルをオープンし, それを1行ずつ読み取りながら, AKARI-CASに対して SQL 文を投げ,その結果を表示するものです.
$cmd
に,Radial Searchを行なうための
適切なSQL文をセットし,
AKARI-CASからSDSS DR8で分光観測された天域にあるIRC天体を
すべて取得してください.$ php getakaribylist.php result.csv
{kind=link}
{kind=link}
{kind=link}
{kind=link}